building a language instructed robotic assistant
tech ·LIRA: Language Instructed Robotic Assistant. A proof of concept to bridge natural language with physical systems. A secondary goal is to also see if existing agent architecture patterns can extend to hardware tools.
challenge of language-instructed robotics
while LLMs have rapidly evolved function calling capabilities, most research and applications have focused on software tools including saas integrations, internal functions, or memory systems acting as tools. The exploration of how these function calling patterns can extend to hardware interactions remains relatively underexplored despite recent developments in this space. There is also an open question around whether LLM agents can serve as effective intelligence and orchestration layers for physical robots handling complex decisions, error recovery, and multi-modal reasoning in a real world setting. Wanted to explore this problem and develop an opinion on these systems, so built a small poc for it.
building the skeleton
this is how the overall architecture looks like
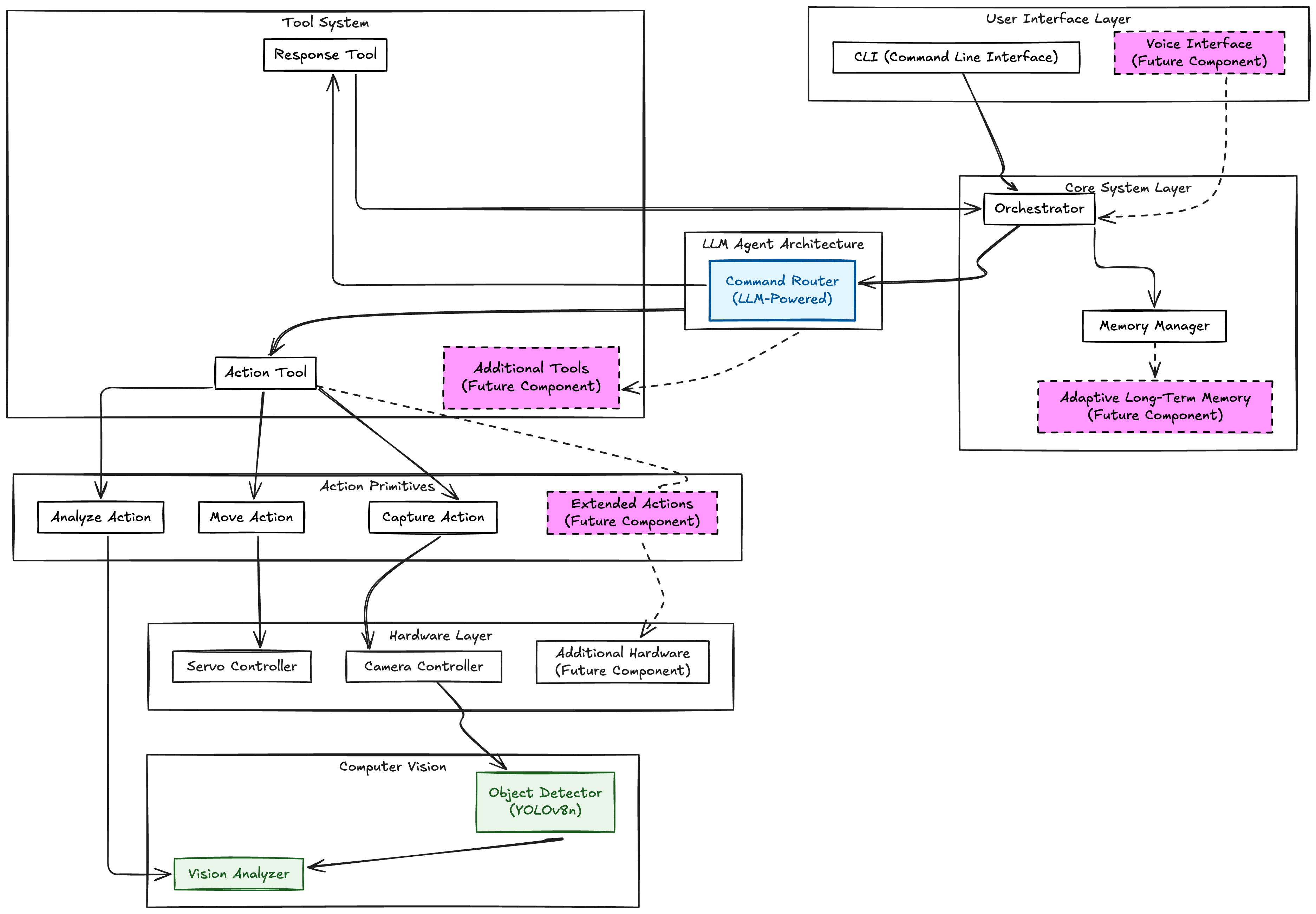
LIRA’s architecture takes an agentic approach to robot building, at least for the orchestration and intelligence layer. Unlike traditional robotic systems that follow deterministic sequences of actions, this pattern allows the robot to create its own series of actions using the tools it has available. It also has memory that it can use for context in decision making.
the system follows this flow:
user provides natural language input → command router (powered by an LLM) interprets the command → router decides whether to execute actions or provide a conversational response → If actions are needed, the router breaks down complex commands into atomic actions → these actions include servo movement, camera capture, and object detection all isolated into separate action primitives that can be executed independently or in combination → results are aggregated and presented back to the user
this architecture allows for flexibility in command interpretation while maintaining control over physical components. The adaptive long-term memory is still a work in progress as are additional tools. But the system is designed for extensibility, both in the hardware layer and the tool system.
building the orchestrator
the orchestrating function is a combination of the router which acts as the brain of the agent, and the orchestrator which joins the user command, the router decisions and the eventual output together. It takes your natural language input and figures out whether you want to chat or actually move the robot around.
a lot of this was prompt engineering, creating the right JSON structure for downstream tools to consume and giving the agent a narrative to think about. I was tempted to use something like langgraph/langchain to build this scaffolding but wanted to to see if I can avoid bloated frameworks for this build lol. To my surprise, I could get a highly customizable orchestration layer ready in no time (thanks to cursor)
prompt engineering gets interesting when the output affects physical systems. Through trial and error, I found a few ground rules which work well while building agents:
explicit action schemas: Clearly defining the format and parameters for actions
multi-step planning: Encouraging the LLM to break down complex commands
safety constraints: Building guardrails into the prompt itself
fallback mechanisms: Providing clear paths for handling uncertainty. this can be a reflection loop within the agent, or intermediate errors which get relayed at the end of the agent graph
this json contract along with a few-shot examples is fed to the llm prompt
{
"type": "action",
"actions": [
{"tool": "action_tool", "action": "move", "direction": "left"},
{"tool": "action_tool", "action": "capture", "label": "left_view"},
{"tool": "action_tool", "action": "analyze"}
]
}
the structured router response is read and orchestrated to the required tools. the llm is only responsible to break down instructions into actions and the correct sequence for those actions. the orchestrator is responsible for executing the actions and aggregating the results.
here’s how a baby version of it works conceptually:
class CommandRouter:
def route_command(self, user_input: str, chat_context: List[Dict] = None) -> RoutingDecision:
# Use LLM to determine routing and actions with chat context
prompt = f"""You are a robot assistant router that plans and decomposes commands into atomic actions.
Current command: "{user_input}"
Return ONLY this JSON format:
{
"type": "action" or "conversation",
"actions": [list of actions if type is "action", empty list if "conversation"]
}
Available Atomic Actions:
1. "move" - Move camera to a specific direction
2. "capture" - Take a photo in the current direction
3. "analyze" - Analyze the most recently captured image"""
# Send to LLM API and parse response
# Response goes to orchestrator
this naive router’s job is simple: look at what you said, decide if you want actions or just conversation, and if actions, break them down into the atomic steps the robot can actually do.
the orchestrator ties it all together. It takes the router’s decision and makes it happen:
class RobotOrchestrator:
def process_command(self, user_input: str) -> str:
# Add to memory
self.memory.add_user_message(user_input)
# Route command with chat context
chat_context = self.memory.get_chat_history(limit=5)
decision = self.router.route_command(user_input, chat_context)
# Execute tools if needed
if decision.use_tools:
for action in decision.tool_actions:
result = self.action_tool.execute(**action)
self.memory.add_tool_output(result)
# Generate response
response = self._generate_response(user_input)
self.memory.add_assistant_message(response)
return response
So the flow is user input → router decides what to do → orchestrator executes the plan → tools do the physical work → response gets generated. the LLM doesn’t just generate text, it’s making decisions about what physical actions to take.
tools as the interface between language and action
the key is treating physical capabilities as “tools” that the LLM can use. This approach has several advantages:
abstraction: LLM doesn’t need to understand hardware details
composability: complex actions can be built from simple primitives
extensibility: new tools can be easily added
error handling: tools can manage their own failure modes
currently implemented three core action primitives:
move: control servo positioning (left, center, right)
capture: take photos with the camera
analyse: detect objects using a pre-trained cv model (yolov8n)
all these primitives are currently a part of a single global action tool and can be combined to execute complex commands like “scan the room” or “look left and tell me what you see”
the analyze tool and how its used for object detection
the analyze tool is what gives the robot its “eyes”. It takes the most recently captured image and runs it through a naive computer vision pipeline to understand its surroundings
here’s how the vision analyzer works conceptually:
class VisionAnalyzer:
def analyze_image(self, image: np.ndarray, position: str) -> Dict[str, Any]:
if self.use_yolo:
objects = self._yolo_object_detection(image)
# Generate spatial description
spatial_description = self._generate_spatial_description(objects, position)
return {
"objects": objects,
"spatial_description": spatial_description,
"position": position,
"total_objects": len(objects)
}
the tool is not just detecting objects, its creating structured representations that the LLM can reason about. Instead of feeding raw pixels to the LLM, the tool responds with clean structured metadata for the LLM to do its analysis with.
this is an example of how the tool response which gets stored in the state of the agent graph.
{
"success": true,
"action": "analyze",
"analysis": {
"objects": [
{
"name": "chair",
"confidence": 0.87,
"spatial_position": "left side"
}
],
"spatial_description": "On the left: chair.",
"position": "left",
"total_objects": 1
}
}
this prevents hallucinations because the LLM only sees what we actually detected, not what it thinks it sees in the pixels. I also wanted to try a hybrid approach of using a CV pipeline tied to an LLM so built it this way.
I’m using YOLOv8n (nano) from ultralytics which is the smallest pre-trained model in the YOLOv8 family but still decently accurate for our poc. This works well on an edge device like raspi.
the hardware tools: capture and servo
the capture tool handles the raspberry pi camera and the servo controls the physical movement. Both are pretty straightforward but have some interesting challenges.
capture tool: raspberry pi camera controller
class CameraController:
def capture_image(self, label: str) -> Dict[str, Any]:
image_array = self.camera.capture_array()
# Convert from RGB to BGR for OpenCV compatibility
image = cv2.cvtColor(image_array, cv2.COLOR_RGB2BGR)
return {
"success": True,
"image": image,
"metadata": {
"resolution": self.resolution,
"label": label
}
}
the tricky part here is managing camera resources on the pi. I kept running into pipeline handler in use errors, so had to add retry mechanisms and proper cleanup of resources.
servo tool: physical movement
class ServoController:
def move_to_position(self, position: str) -> Dict[str, Any]:
target_angle = self.position_map[position] # left: 30°, center: 90°, right: 150°
# Calculate duty cycle for PWM
duty_cycle = self._angle_to_duty_cycle(target_angle)
# Move servo
self.pwm.ChangeDutyCycle(duty_cycle)
return {
"success": True,
"position": position,
"angle": target_angle
}
the servo controller maps named positions (left, center, right) to actual angles and handles the PWM signals to move the servo.
had to brush up on my electronics classes for this one. Servos work by sending PWM signals where the pulse width determines the angle. The math is:
duty_cycle = (pulse_width_ms / period_ms) * 100
where pulse width ranges from 0.5ms (0°) to 2.5ms (180°) and the period is 20ms (50Hz). So for 90° (center), you need a 1.5ms pulse, which gives you a 7.5% duty cycle.
funny how you forget this stuff until you actually need to control hardware.
how it all ties together

looking back at the architecture diagram, you can see how these tools flow together:
orchestrator gets a command like “scan the room”
router breaks it down into atomic actions: move left → capture → analyze → move center → capture → analyze → move right → capture → analyze
action tool executes each primitive:
– servo controller moves the camera
– camera controller captures an image
– vision analyzer processes the image and returns structured data
orchestrator aggregates all the results and generates a response
the beauty is that each tool is isolated which means that the LLM doesn’t need to know about PWM signals or camera pipelines. It just calls move("left") or capture() or analyze().
constraints
setting up the hardware for the first time took some time. Testing if each part works individually, wiring everything up and debugging GPIO issues will be easier for me in the future but as a first timer it was a learning curve.
the object detection model isn’t the best. I’m using YOLOv8n (the nano version) which is designed for edge devices, but it’s still pretty slow. A single detection takes about 1-2 seconds, which adds up when you’re doing room scans. The cheap camera used is also pretty distorted which makes it difficult to detect objects accurately.
the servo is limited in functionality. Can probably add more actuators and degrees of freedom to the system. The camera resource management was also a pain kept getting “pipeline handler in use” errors, so had to add retry mechanisms and proper cleanup. Turns out the pi camera doesn’t like being accessed by multiple processes.
it sometimes hallucinated and broke the system. Had to add guardrails to prevent this, but a reflection module for when errors come is still to be added to make it more robust.
errors are inevitable. servo gets stuck, camera fails to initialize, object detection returns garbage. I had to build pretty robust fallback mechanisms with extensive logging to figure out whats going on lol. The tricky part is deciding when to retry vs when to give up and report an error to the user.
future plans
voice interface instead of command line is one obvious next step to make the interaction more natural. Thinking about adding a transformer-based voice module for speech-to-speech interaction, basically bypassing the text layer entirely and going from speech input to speech output.
adaptive long-term memory, right now the memory is pretty basic just stores chat history. I want to add object memory (remember what was where), spatial memory (build a map of the room), and interaction memory (learn from user preferences).
more tools for the robot both software and hardware. Currently we only have left/center/right positions. I want to add more servo positions (maybe 5-7 positions for finer control), pan/tilt capabilities, maybe even a second servo for vertical movement. on the software side, can the LLM discover new tools or compose existing ones in novel ways? like if it learns that “move left” + “capture” + “analyze” works well, can it automatically suggest “move right” + “capture” + “analyze” for room scanning and this gets stored in some tool memory? (something to explore later)
wrapping up
LIRA is basically a proof of concept to experiment with convergence of llm with robots. The most promising path forward seems to be a hybrid approach where LLMs are used for high-level planning and understanding, specialized systems for low-level control and perception.
as LLMs get better at function calling and hardware becomes more capable, we’ll probably see increasingly sophisticated systems that can translate natural language into physical actions in more complex environments.